Large Generative Model On-Device Deployment & Optimization
Motivation
Convolution-based and language-based models have made significant performance strides in the last decade. Despite these advancements, the rapid growth in model complexity and size has outpaced the progress in AI deployment technologies, necessitating increased attention to model compression for efficient deployment on smaller devices. With a focus on deploying a large convolution-based model for virtual garment warping on a small device, this project introduces post-training compression methods aimed at maintaining original performance while enhancing efficiency.
Introduction
As a member of a team of five, I was responsible for compressing a large generative model (72 million parameters) for a virtual garment try-on system — based on the model proposed by Parser-Free Virtual Try-on via Distilling Appearance Flows (CVPR 2021) — onto an NVIDIA Jetson Nano 4GB. I optimized model efficiency through quantization, pruning, and knowledge distillation, and conducted sensitivity analysis to evaluate each convolution channel and layer concerning compression techniques.

Model
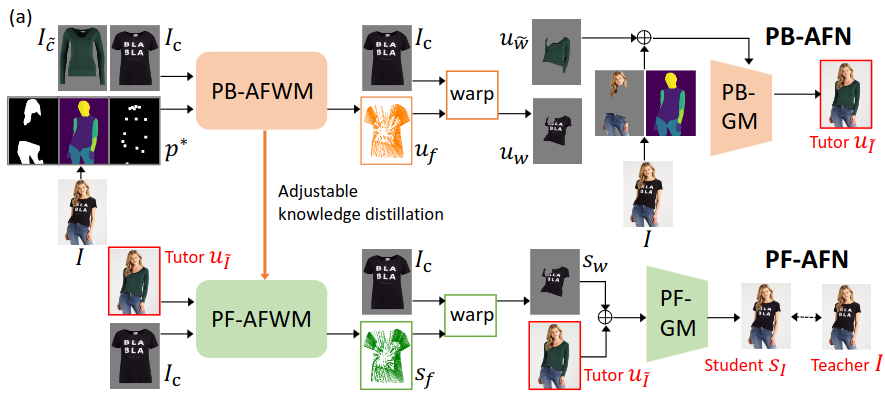
The model chosen for this project is Parser-Free Appearance Flow Network (PFAFN). This model has over 70 million parameters and aims to warp input clothing and person images to output an image of the person wearing the clothing. The model comprises two modules: a generative model (43M parameters) and an appearance flow warping model (29M parameters).
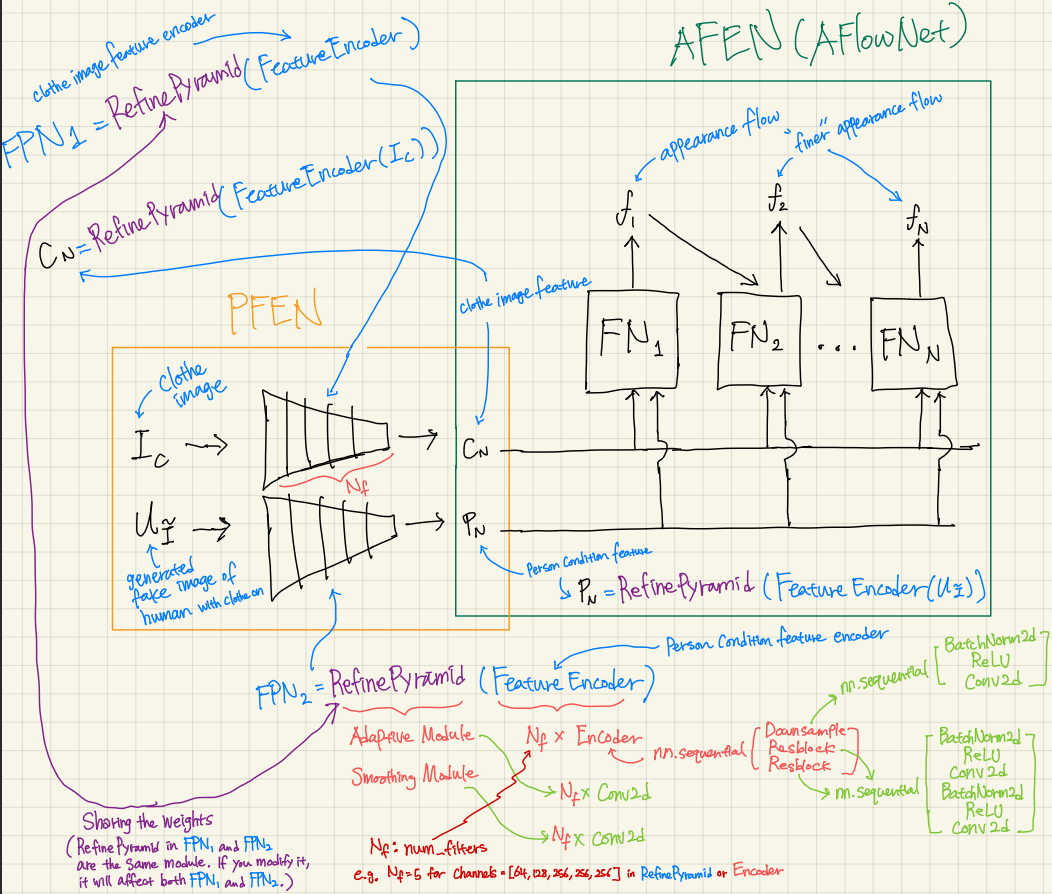
Data
The training data is the clothing image and the image of a person wearing the clothes. Parser-based network PB-AFN randomly selects a different clothing image to synthesize a fake image as the tutor. The tutor output and the clothing image serve as inputs to train the parser-free network PF-AFN, where the generated student output is directly supervised by the real image.

Pruning — Generative Model
We selectively reduced or "silenced" the activity of each block via structured pruning to observe how output quality changes and identify which aspects of the output are most affected when different levels of the system are less active.




Pruning — Warping Model
I performed a filter-wise structured pruning sensitivity analysis on AFWM's human condition feature encoder and clothing image feature encoder. I pruned the first 64 filters per layer, systematically evaluating one filter at a time. Through this analysis, I concluded that mid layers in the encoders are the least sensitive to pruning, while initial layers are the most sensitive as they capture the highest-level global features. I propose that carefully devised filter-wise pruning targeting non-key-player filters could result in model compression without compromising performance.
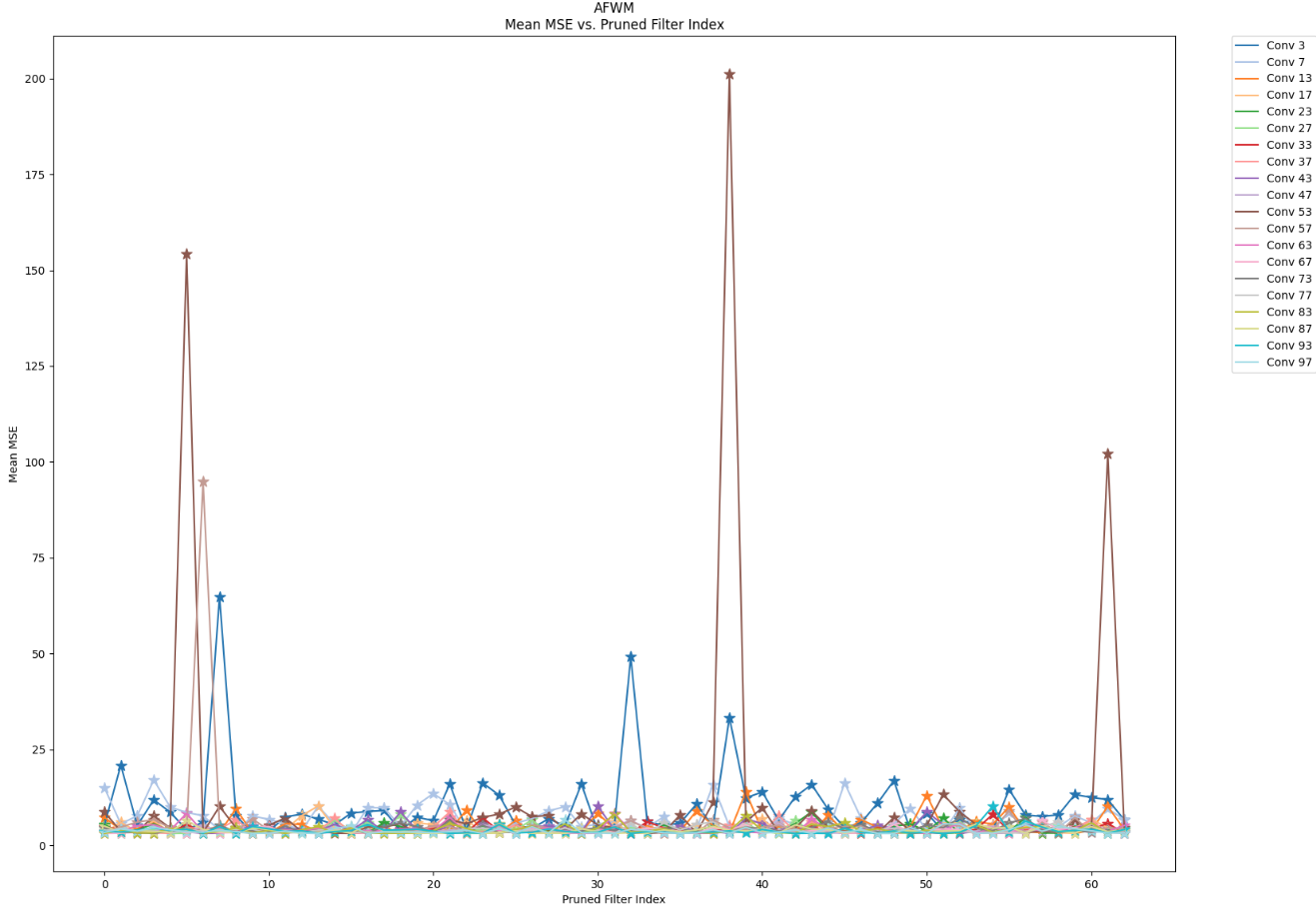
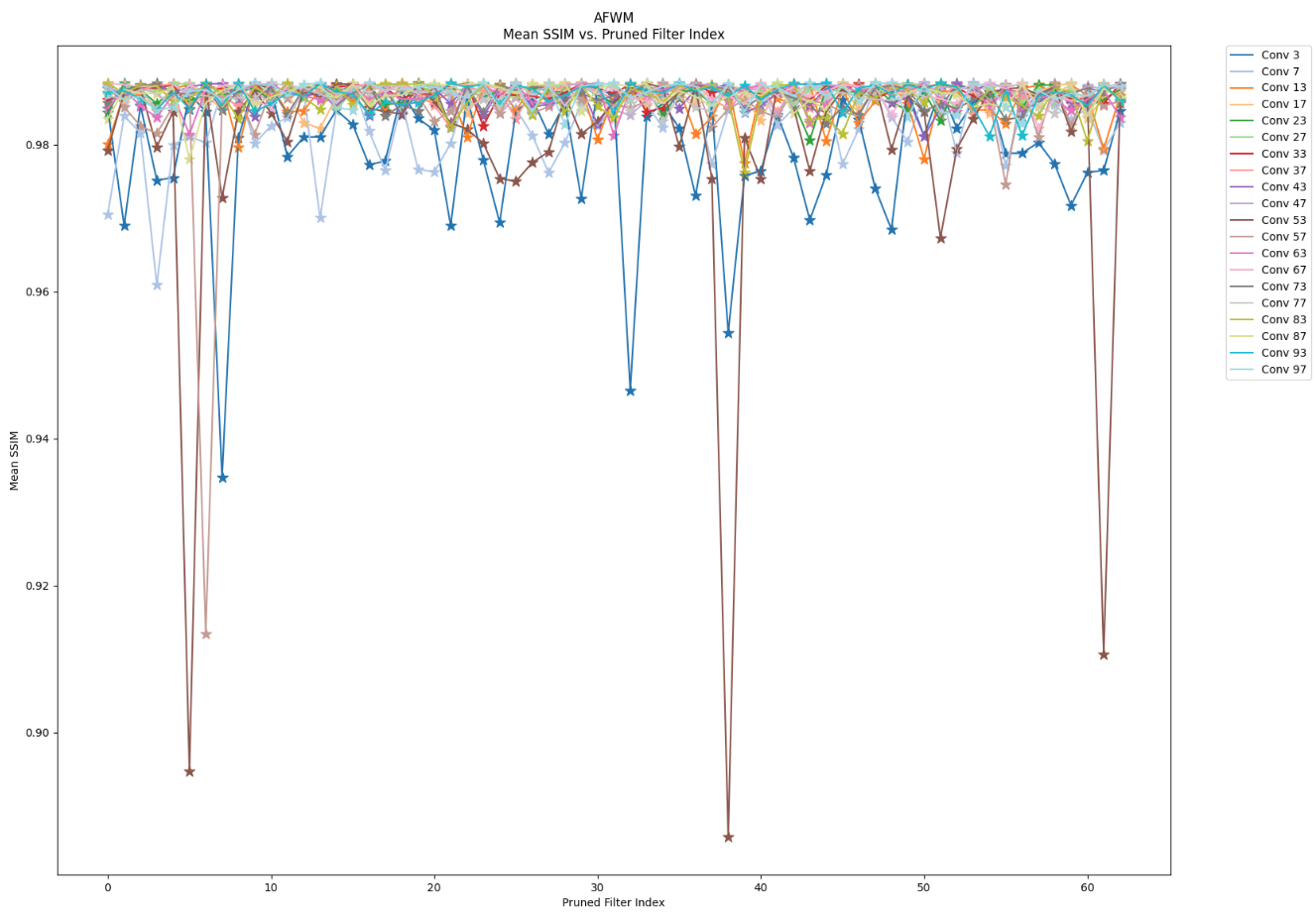
Knowledge Distillation
We compressed our generative model and warp model separately by reducing the number of channels within their respective convolution layers, then fine-tuned the compressed student model using output signals from the original teacher model via a custom loss function.
Generative Model Distillation
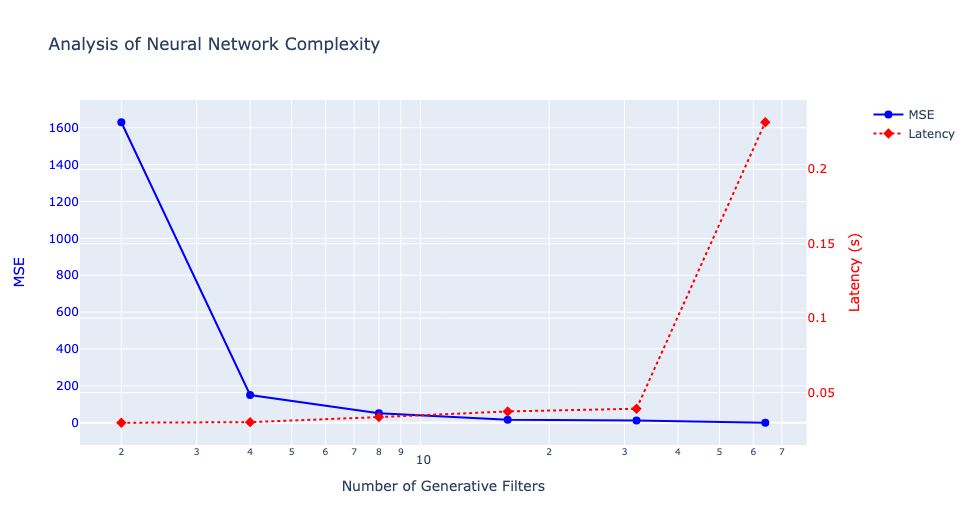
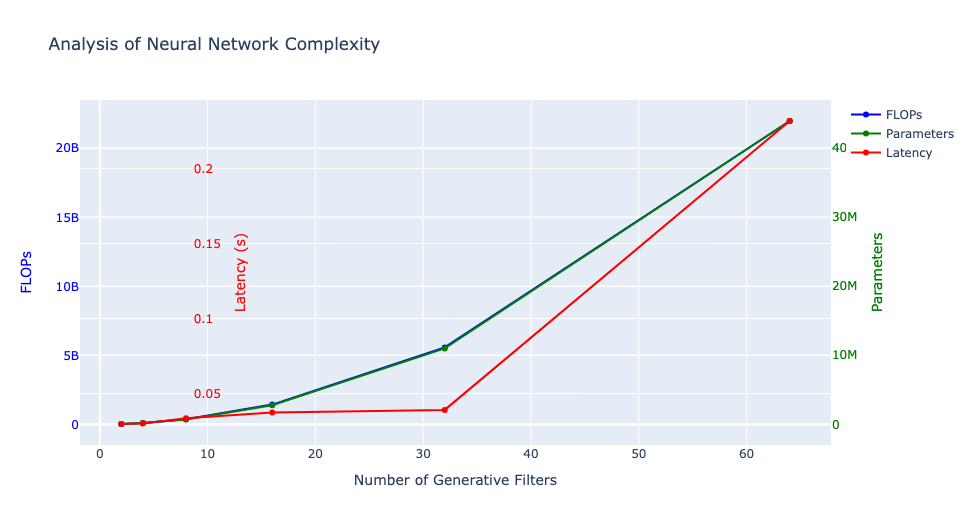
We conducted tests with ngf (number of generative filters) values ranging from 2 to 64 — the original model used ngf=64. We then utilized a custom loss function for fine-tuning the compressed student model.


Warping Model Distillation
I compressed the warping model (29M parameters) by reducing the number of channels in its convolution layers, modifying the configuration from [64, 128, 256, 256, 256] to alternative combinations, and evaluating each against performance benchmarks.



Distillation Performance