Q&A Chatbot with LLMs via Retrieval Augmented Generation
Motivation
Q&A systems with large language models (LLMs) have shown remarkable performance in generating human-like responses. However, LLMs often suffer from hallucination and generate plausible but incorrect information.
Introduction
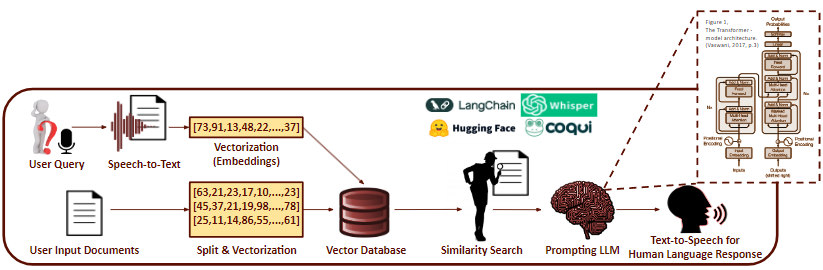
To address this issue, we developed a Q&A chatbot system that leverages retrieval-augmented generation (RAG). RAG allows users to vectorize and store documents (PDF format) in a grounded database, and conducts similarity and semantic search to retrieve the most relevant information when a user asks a question. The retrieved information is then converted into a human-like response by the LLM.
Research Challenges
- Choosing an LLM for the human-like text generation component.
- Selecting an embedding model to vectorize the documents.
- Generalizing the retrieval system to handle different document types.
- Further mitigating hallucination in the LLM.
- Finding evaluation metrics for retrieval system performance.
- Fine-tuning the LLM if performance is not satisfactory.
- Optimizing inference time and memory usage.
- Developing a user-friendly web application interface.
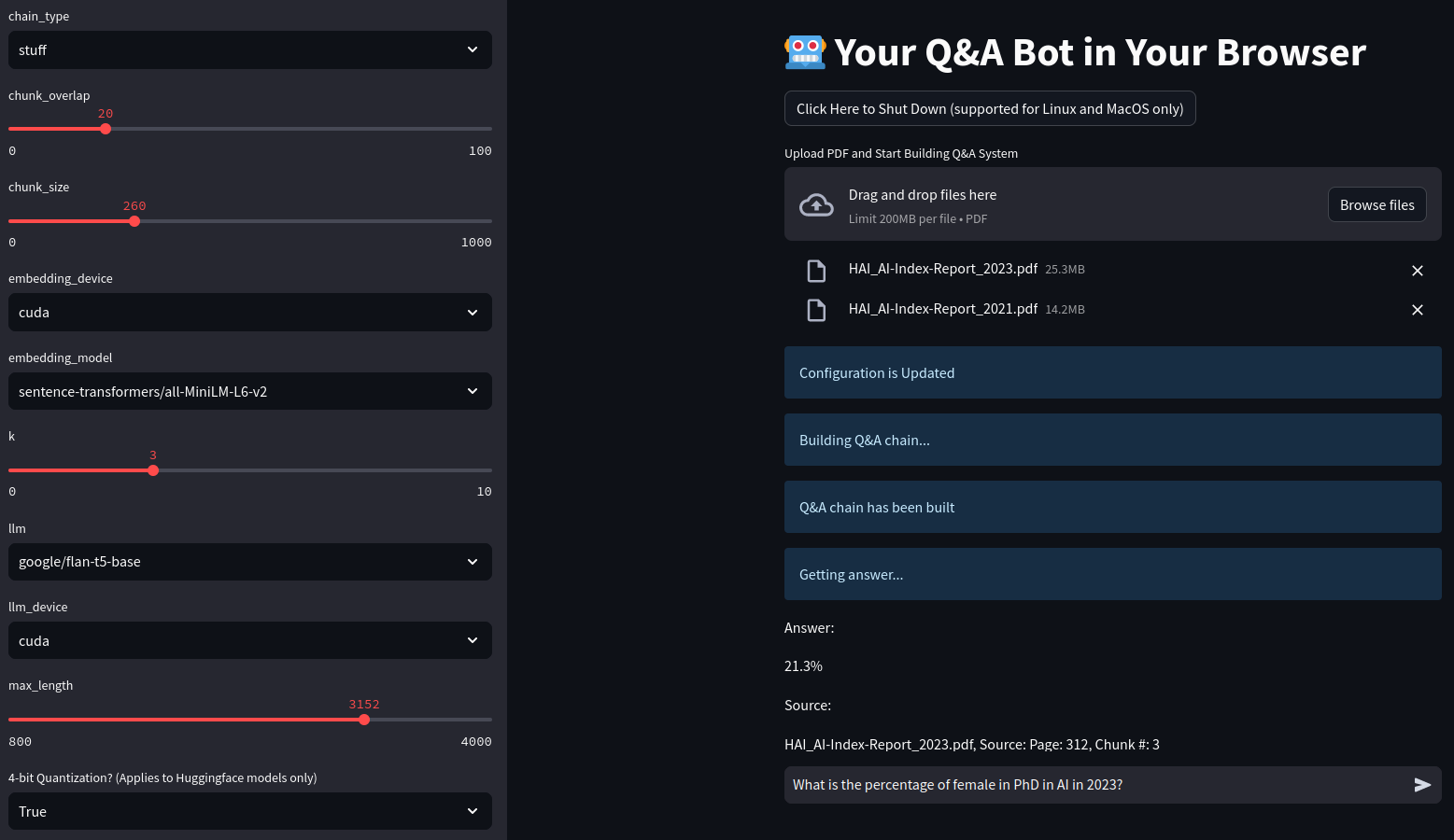
Web Application
We developed a web application that allows users to upload PDF documents and ask questions. The application focuses on refining inference time, memory usage, and user interface.